
Nature Communications | 朱正江团队开发结构信息驱动的深度生成模型MetGenX用于代谢物鉴定
在代谢组学研究中,未知代谢物的结构解析仍是当前领域的主要瓶颈之一。基于数据库的谱图匹配被认为是代谢物注释的金标准,但其适用范围仅限于具有参考谱图的已知代谢物。对于未知代谢物的注释,无论是“已知的未知代谢物”(已存在于结构数据库中但缺乏参考谱图)还是“完全未知代谢物”(具有全新结构),仍然构成代谢组学研究中的根本性挑战。随着人工智能技术的发展,深度生成模型为探索已知化学空间之外的新型结构提供了新的可能。然而,由于高质量参考质谱数据的匮乏,人工智能方法在代谢物注释中的潜力尚未得到充分发挥。
近日,中国科学院上海有机化学研究所生物与化学交叉研究中心朱正江团队在Nature Communications杂志在线发表了题为“Structure-informed deep generation enables de novo metabolite annotation in untargeted metabolomics”的研究论文(https://www.nature.com/articles/s41467-026-72149-6)。该研究提出了一种基于结构模板的深度生成模型MetGenX,实现了基于代谢组学数据的大规模代谢物鉴定,并有助于发现化学结构数据库中未收录的全新代谢物。

与传统方法不同,MetGenX并不直接基于查询质谱碎裂谱图进行结构解析,而是采用一种模态表示转换策略:首先通过谱图相似性搜索,将查询谱图映射到一组结构相似的代谢物;随后以这些检索到的结构为模板,指导从头生成过程。基于谱图相似度获得的结构相似化合物可作为重要的先验信息,为目标化学结构的生成提供有效约束。该策略将代谢物鉴定由传统的“谱图到结构”解析,转化为“结构到结构”的生成过程,通过引入结构模板弥合实验谱图与结构生成之间的差距,从而显著提升模型性能。
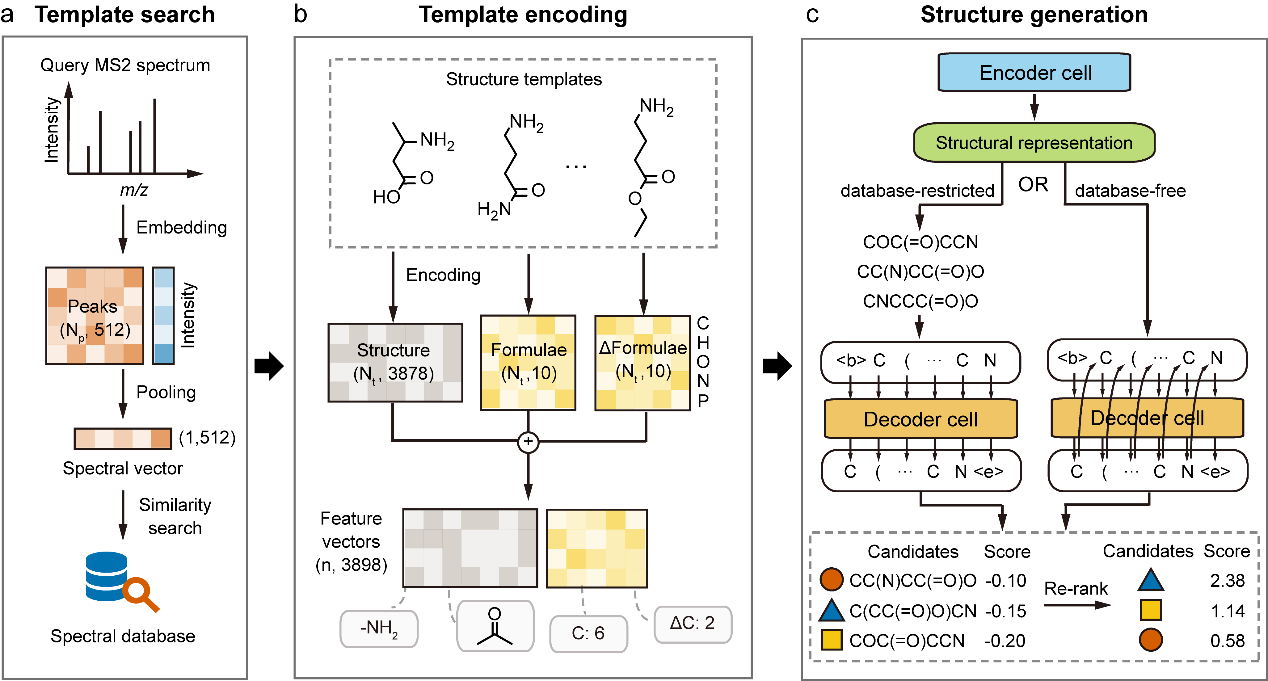 图1. 基于结构模板的深度生成模型MetGenX在质谱碎裂谱图结构解析中的应用
图1. 基于结构模板的深度生成模型MetGenX在质谱碎裂谱图结构解析中的应用
通过这一策略创新,MetGenX实现了在同一模型架构上,对结构生成模型进行结构预测任务的预训练和谱图解析任务的微调,从而使得模型可以利用大型化学结构数据集进行模型训练。MetGenX首先在超过200万个生物相关的化学结构数据集上进行了预训练,并使用NIST20中标准质谱碎裂谱图数据库对模型进行了微调,以适应基于质谱碎裂谱图的代谢物结构解析任务。通过“预训练-微调”的两阶段训练,MetGenX克服了质谱碎裂谱图训练数据不足的问题,实现了实现高准确性的代谢物结构注释,同时具备探索新型代谢物的能力。
在NIST20谱图数据库的独立测试集中,MetGenX在1388张质谱碎裂谱图上分别取得了55.9%的Top-1准确率和76.1%的Top-3准确率。在五种真实生物样本的1681张质谱碎裂谱图上,其Top-1和Top-3准确率进一步提升至68.5%和89.2%。与其他常用代谢物注释工具相比,MetGenX在注释准确率和覆盖率方面均表现出明显优势。值得注意的是,作为一种基于结构模板的生成模型,在正离子模式下训练的MetGenX可直接迁移至负离子模式质谱碎裂谱图的解析,而无需额外训练。在2319张负离子模式生物样本谱图上,MetGenX仍取得了60.7%的Top-1准确率和82.5%的Top-3准确率,体现了其在复杂生物样本中的解析能力以及跨离子模式的良好泛化性能。此外,为模拟真实代谢物注释流程,作者构建了一个基于MetGenX的多步注释工作流,并应用于小鼠肝脏非靶向代谢组学数据分析。通过该流程,研究成功发现并验证了两个未被现有主流代谢组学数据库收录的代谢物,进一步证明了MetGenX在新型代谢物发现方面的潜力。
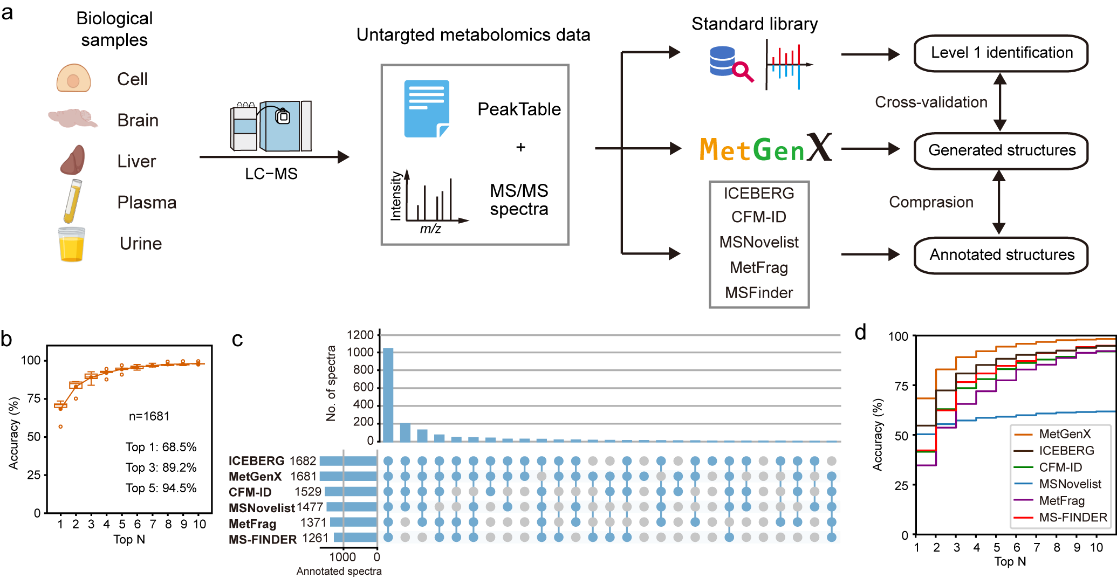
图2. MetGenX在真实生物样本中的代谢物注释性能评估
综上所述,MetGenX通过人工智能技术实现了大规模代谢物注释与未知代谢物的发现,有助于解析代谢组学数据中的“暗物质”,提升数据集的注释覆盖度,从而推动非靶向代谢组学研究的进一步发展。中国科学院上海有机化学研究所生物与化学交叉研究中心朱正江课题组博士研究生王洪淼是论文的第一作者。朱正江研究员为论文的通讯作者。中国科学院上海有机化学研究所生物与化学交叉研究中心为第一单位。上述工作的相关技术已经申请了国家发明专利与国家软件著作权,相关技术的商业用途需要联系朱正江研究员进行授权使用。
该工作得到了国家自然科学基金委、中国科学院、上海市科委和上海尚思自然科学研究院的资助。
原文链接:https://www.nature.com/articles/s41467-026-72149-6
附件下载:
